



In theory, each new or modified function should be tested. Often, the initial reaction is to have one unit test per code change. It's not that simple however.
Writing unit tests is time consuming, and only makes sense for functions containing non-trivial code or a minimum level of computational complexity. For example, writing unit tests for getter and setter functions is an inefficient use of time and produces little value.
If a function is tested correctly, it does not imply the code calling it will work (in most cases because the function is called using illegal parameters) - Meaning, even if many unit tests are available, a system test may still be necessary.
Also, just because a computation is correct, doesn't mean the main application results are meaningful. Many times, I have seen an entirely correct result, which once displayed by the end application, is completely unusable.
Take for example exceedingly large results, containing far too many false positives or false negatives. Such results give the false impression of weak unit tests and that only system tests should be written. This is of course inaccurate, as unit tests are the only practical method for validating rarely occurring situations, such as complex error cases.
Back to the main question: Are Unit Tests necessary, or do System Tests suffice?
- Given a specific function, should we write a unit test or a system test?
- And if possible, is a system test preferred, and how do you know?
The simplest approach - Use a code coverage tool
- Execute a system test
- Analyze the coverage of the result
- Determine if additional unit tests are necessary
The above method is a bit contradictory, as it requires you to first test to see if the test was even necessary. The real problem however is the required change in the development workflow. Usually, the development team codes the new features first, after which they write unit tests. Then in a second phase, the testing team validates the code change. If the coverage information is used to determine the necessity of unit tests, then developers would have to write tests for functionality developed after the product was tested - in other words - potentially weeks after the coding phase. Also not efficient.
Another approach - Perform a static analysis, identifying functions difficult to test using system tests
- Count the minimal number of branches executed starting from main() until the function to test is reached
- Create a ranking list of all functions and compare it with known functions requiring unit tests.
Seem complicated? It doesn't have to be.
Let's give this sample a try:
The following code is converting a string passed as an argument of the program to upper case. It's easy to see, that to execute the function, it is necessary to call upper_string() using a non-empty string, and that to execute upper_string() the program needs to be called with exactly one argument. We only then have to take one branch in a set of four. print_usage() is easier to execute from the main application because it only requires one branch of a set of two to execute.
[code language="cpp"]
#include stdlib.h;
#include stdio.h;
#include string.h;
char upper_char( char c )
{
if ( c >= 'a' && c <= 'z' )
c = c + ( 'A' - 'a' );
return c;
}
void upper_string( char *text )
{
while ( *text )
{
*text = upper_char( *text );
text++;
}
}
void print_upper( const char *text )
{
char *t = strdup( text );
upper_string( t );
printf( "%sn", t );
free( t );
}
void print_usage()
{
printf( "upper.exe argumentn" );
}
int main( int argc, char *argv[] )
{
if ( argc != 2 )
{
print_usage();
return 1;
}
else
{
print_upper( argv [1] );
return 0;
}
}
[/code]
To compute this metric we have to create a graph, from the binary code generated by the compiler, on which:
- A vertex is an instruction or a function name
- An edge is indicating the next potential instructions or functions.
This is the result for our sample:
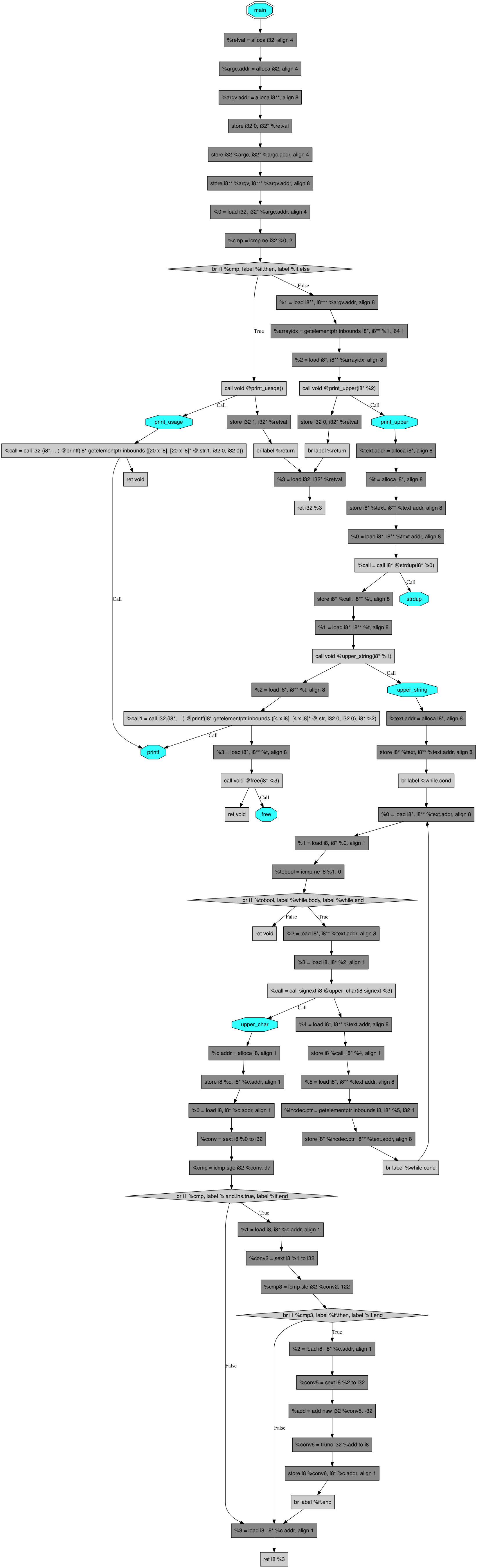
To compute the metric for an instruction, we start at the main() function, jump from vertex to vertex until the target instruction is reached, and update the metric as follows:
- We initialize the main() function to 1.
- When reaching a conditional branch, we double its value because one of the two branches had to be selected.
- For a switch/case, as well as for a conditional branch, we multiply the metric by the number of cases.
- For all other instructions, we leave the metric unchanged.
Using the Bellmann-Ford algorithm it is possible to compute this metric for all functions with a complexity near O(I) (I number of instructions in the program, we can ignore the number of edges since in most cases they are lower than two).
The result of our sample program:
| Function | Metric |
| upper_char | 4 |
| upper_string | 2 |
| print_usage | 2 |
| print_upper | 2 |
| main | 1 |
As expected, upper_char() is more difficult to call from main(), therefore writing a unit test for upper_char() should be preferred to writing a unit test for print_usage().
To evaluate the limits of this metric, let's apply it to the Squish Coco parser sample:
| Function | Metric |
| sign(double) | 17179869184 |
| isDigit(char) | 2147483648 |
| Error::get_id() | 2147483648 |
| Variablelist::get_value(char const*, double*) | 1610612736 |
| isalpha(int) | 1073741824 |
| __istype(int, unsigned long) | 1073741824 |
| isascii(int) | 1073741824 |
| factorial(double) | 637534208 |
| isAlpha(char) | 536870912 |
| Parser::eval_variable(char const*) | 402653184 |
| __isctype(int, unsigned long) | 268435456 |
| isdigit(int) | 268435456 |
| isDigitDot(char) | 268435456 |
| Parser::parse_number() | 134217728 |
| isDelimeter(char) | 134217728 |
| Parser::parse_level10() | 67108864 |
| Parser::eval_function(char const*, double const&) | 67108864 |
| Parser::parse_level9() | 33554432 |
| toupper(char*, char const*) | 33554432 |
| Parser::eval_operator(int, double const&, double const&) | 33554432 |
| Variablelist::add(char const*, double) | 33554432 |
| toupper(int) | 33554432 |
| Variablelist::get_id(char const*) | 33554432 |
| Parser::parse_level2() | 16777216 |
| Parser::parse_level5() | 16777216 |
| Parser::parse_level6() | 16777216 |
| Parser::parse_level4() | 16777216 |
| Parser::parse_level3() | 16777216 |
| Parser::get_operator_id(char const*) | 16777216 |
| Parser::parse_level7() | 16777216 |
| Parser::parse_level8() | 16777216 |
| Error::get_col() | 8388608 |
| Parser::parse_level1() | 8388608 |
| Error::get_msg() | 4194304 |
| Error::Error(int, int, int, ...) | 4194304 |
| Error::msgdesc(int) | 4194304 |
| Parser::getToken() | 2097152 |
| Parser::col() | 2097152 |
| Parser::row() | 1048576 |
| Error::get_row() | 1048576 |
| Parser::parse(char const*) | 131072 |
| Parser::~Parser() | 16 |
| Parser::~Parser() | 16 |
| Variablelist::~Variablelist() | 16 |
| Variablelist::~Variablelist() | 16 |
| Variablelist::Variablelist() | 4 |
| Variablelist::Variablelist() | 4 |
| Parser::Parser() | 4 |
| Parser::Parser() | 4 |
| main | 1 |
This result is also pertinent as:
- We can clearly see functions like factorial(), VariableList::get_value() or Error::get_id(), which are called by the parser code after a successful parsing, are considered as candidate for a unit test.
- Whereas the call of Parser::parse() is on the bottom of the list, and is easy to test using a system test.
But this sample also demonstrates some limits of this simple computation:
- It only takes into account the shortest path from main() to a function. It ignores that a function can be executed several times by different branches. This is the case with isDigit() or isAlpha() which are called for each character read.
- A function which is difficult to execute is not always a function which is important to test. In fact, object-oriented programmers are often using getter and setter functions for member variables, or only simple wrappers like isAlpha(), which is only a standard C function isalpha() call. These functions are often a leaf in our graph, but are less important to test as they are only a simple wrapper. Certainly using a code complexity metric would enable filtering out all trivial functions.
Conclusion
With reasonable precision, we can conclude it is possible to predict if a unit test or system test should be used to verify functionality, even before writing a test. This is of course less accurate than trying to first validate it through an application test, and as a fallback, covering it as a unit test, however this approach is not applicable for complex applications.
This also opens another possibility - measuring the need for testing by combining tests with a code complexity metric. During conception, combining both metrics makes it possible to identify functions which do not require tests (due to triviality) as well as who should write the test (a developer in the case of unit tests or an application tester for system tests).



